





AI and machine learning (ML) are constantly evolving, leading to a flood of new tools and techniques. This rapid pace of change can make it difficult to keep up and understand the nuances of ML concepts. In this article, we aim to clarify some common misunderstandings about MLOps and real-world machine learning.

#Myth 1 : MLOps is just about automating tasks.
Reality: MLOps is a holistic approach to ML systems, involving people, processes, and technologies. It goes beyond automation to encompass the entire ML lifecycle and foster collaboration. It sets of principles that guide the development and operation of reliable ML systems. It emphasizes collaboration, encompasses the entire ML lifecycle, and leverages automation to streamline processes.
This example provides a basic understanding of MLOps principles in action:
Python Code Snippets Illustrating MLOps Principles :
# Principle 1: Collaboration and Communication (
#Version Control with Git:
!git init
!git add .
!git commit -m "Initial commit"
# Principle 2: Reproducibility
# Data Versioning with DVC (Data version control)
!pip install dvc
# Track data files
!dvc add data/
!git add dvc.yaml
!git commit -m "Add data files to DVC"
# Principle 3: Continuous Integration and Continuous Delivery (CI/CD)
#CI/CD with GitHub Actions (Simplified)
name: ML Workflow
on:
push:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v3
with:
python-version: 3.9
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Train model
run: |
python train.py
- name: Test model
run: |
python test.py
- name: Deploy model (simplified)
run: |
# Deploy the model to a serving layer (e.g., using a cloud platform or a local server)
Remember, MLOps is a comprehensive practice that goes beyond the code, some of this principles are listed as comments in this code, to illustrate how MLOps principles guides the code redaction via good practices.

#Myth 2 : Getting machine learning models into production always takes months.
Reality: While complex projects can take time, with efficient processes and the right tools, it's possible to deploy models much faster. Iterative approach, like developing not Minimum Viable Products (MVPs) but Minimum Viable Prediction 😂 , can significantly accelerate model deployment.
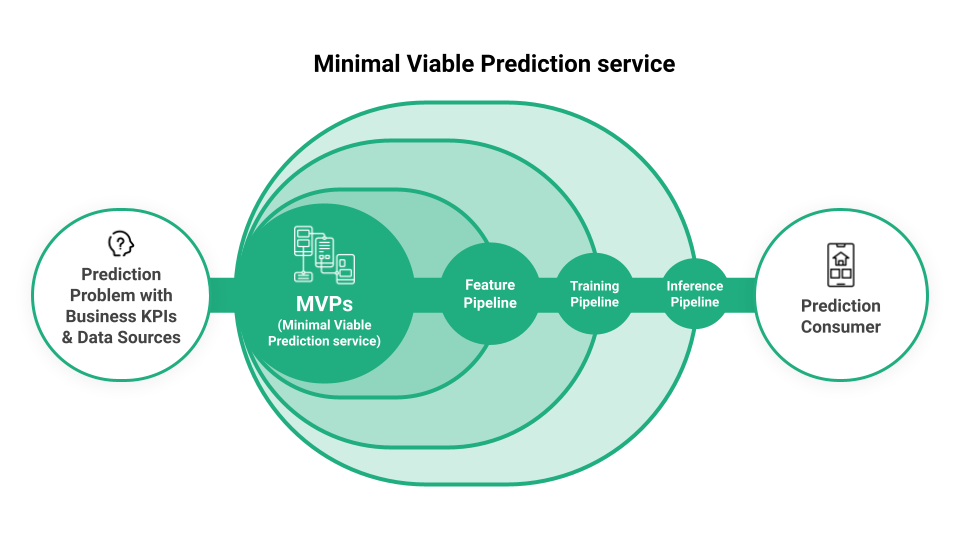
While model development is crucial, it's only one part of the overall machine learning journey. Deploying models into production can be a lengthy process, with many companies taking over a month. This delay often stems from a lack of robust systems for managing data flow within the ML lifecycle.
To address this, organizations should focus on building a unified infrastructure that connects feature, training, and inference pipelines. This approach, exemplified by the concept of Minimal Viable Production Services (MVPs), enables rapid model deployment and evaluation in a real-world setting. MVPs, by incorporating feature stores and model registries, allow for quick feedback on model performance and facilitate continuous improvement
Let me explain you, with a code 😂 :
# Simplified MVPs Example: Feature Pipeline, Training Pipeline, Inference Pipeline
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import joblib # For simple model saving (replace with a proper model registry in production)
# --- Feature Pipeline (Simplified) ---
# (In a real scenario, this would involve data loading, cleaning, transformation, and feature engineering)
def load_and_preprocess_data():
"""Loads sample data and performs basic preprocessing."""
# Replace with your actual data loading logic
data = pd.read_csv('data.csv')
# ... (Data cleaning and transformation steps) ...
X = data[['feature1', 'feature2']] # Features
y = data['target'] # Target variable
return X, y
# --- Training Pipeline (Simplified) ---
def train_model(X_train, y_train):
"""Trains a simple linear regression model."""
model = LinearRegression()
model.fit(X_train, y_train)
return model
# --- Inference Pipeline (Simplified) ---
def make_prediction(model, new_data):
"""Makes a prediction using the trained model."""
prediction = model.predict(new_data)
return prediction
# --- MVPs: Putting it all together ---
def mvp_pipeline():
"""
Executes the entire MVP pipeline: feature engineering, training, and prediction.
"""
# 1. Feature Pipeline
X, y = load_and_preprocess_data()
# 2. Split data (Simplified)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. Training Pipeline
trained_model = train_model(X_train, y_train)
# 4. Save the model (Simplified)
joblib.dump(trained_model, 'model.pkl') # Replace with a proper model registry
# 5. Inference Pipeline (Simplified)
new_data = [[1.5, 2.0]] # Example new data
prediction = make_prediction(trained_model, new_data)
print(f"Prediction: {prediction}")
if __name__ == "__main__":
mvp_pipeline()
Explanation and Simplifications:
Data Handling:
load_and_preprocess_data()is simplified. In a real scenario, this would involve complex data loading, cleaning, transformation, and feature engineering.Data is assumed to be in a CSV file.
Model Training:
A simple Linear Regression model is used for illustration.
Model training and evaluation are simplified. In a real scenario, more rigorous evaluation metrics and hyperparameter tuning would be necessary.
Model Saving:
joblib.dump()is used for basic model saving. In production, a dedicated model registry (e.g., MLflow, TensorFlow Model Registry) would be used for versioning, tracking, and serving models.
Inference:
- The inference pipeline demonstrates how to use the trained model to make predictions on new data.
Key Points:
This code provides a basic framework for an MVP pipeline.
Each component (feature pipeline, training pipeline, inference pipeline) should be further developed and refined based on the specific requirements of the ML problem.
This example focuses on the core concepts of the MVP approach, while simplifying certain aspects for better understanding.
In a real-world scenario, more advanced techniques would be used for data handling, model training, and deployment.

Hey guy, I feel already tired so see you in the next episode for the 3 others myths, soon, cheers ! 😂
Before going, I just want to remind you this
Feedback is welcomed.
And as always, use AI responsibly.
If you like this content please like it ten times, share the best you can and let a comment or feedback.
@#PeaceAndLove