


ML Ops Universe to Pipeline Architecture
MLOps: Automation pipelines in machine learning


Every machine learning (ML) practitioner eventually realizes that building a model in a Google Colab Notebook is only a small portion of the overall endeavor. The real thing is preparing a pipeline that transforms your data from its unprocessed state to forecasts while keeping responsiveness and flexibility. Data scientists and machine learning engineers then become interested and begin seeking such implementations. The best practices and patterns in the industry have already provided answers to many problems in developing machine learning pipelines and systems.

To apply DevOps ideas to ML systems (MLOps), data scientists and ML developers are the target audience for this article. MLOps is a culture and practice in machine learning (ML) engineering that tries to combine the development (Dev) and operation (Ops) of ML systems. Being an advocate for automation and monitoring at all phases of ML system development, such as integration, testing, releasing, deployment, and infrastructure management, is what it means to practice MLOps.
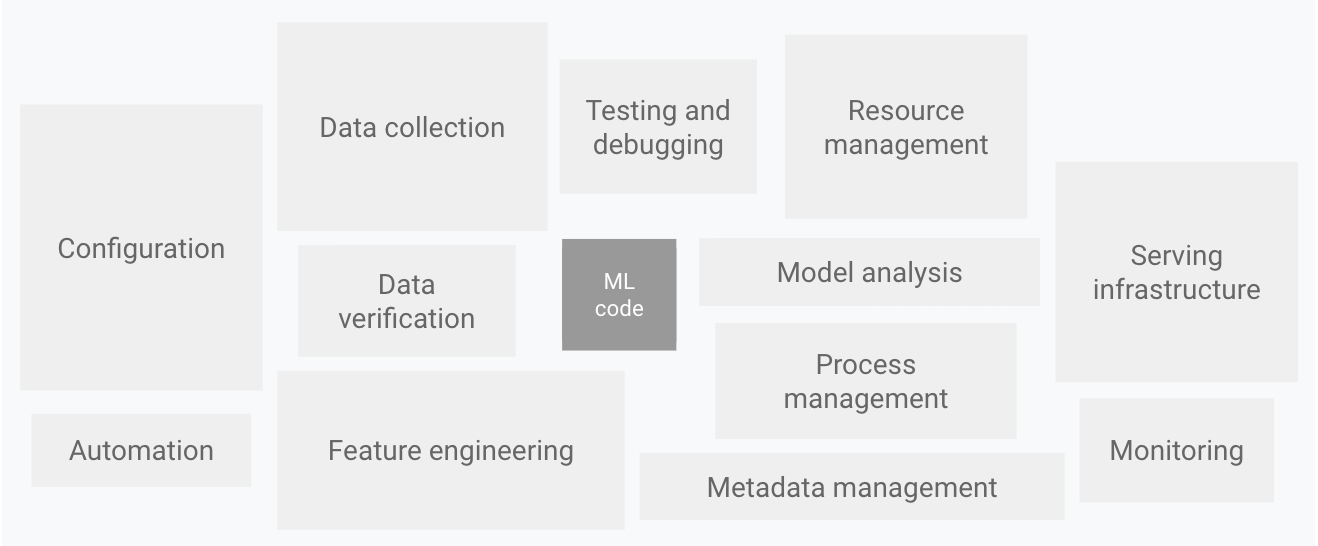
The configuration, automation, data collecting, data verification, testing, and debugging, resource management, model analysis, process and metadata management, serving infrastructure, and monitoring are shown as the remaining components of the system in this figure.
You can apply DevOps techniques to ML systems (MLOps) to create and manage sophisticated systems like these. This article discusses ideas like CI, CD, and CT in ML that you should take into account while setting up an MLOps environment for your data science practices.
DevOps techniques to ML systems (MLOps)
Note: before going deep into the concepts just keep in mind that an ML system is a software system, comparable procedures apply to ensure that ML systems may be dependably created and run at scale.
However, the following are some ways that ML systems are different from software systems:
Teamwork: Data scientists or ML researchers who concentrate on exploratory data analysis, model creation, and experimentation are typically a part of an ML project's team. These individuals might not be skilled software engineers capable of creating services of a production caliber. Let me just laugh
Development: The nature of ML is exploratory. To quickly determine which features, algorithms, modeling strategies, and parameter configurations work best for the issue, you need to experiment with a variety of them. Tracking what worked and what didn't, and preserving reproducibility while optimizing code reusability, are difficult tasks.
Testing: Compared to testing other software systems, testing an ML system is more involved. You need model validation, trained model quality evaluation, and data validation in addition to the usual unit and integration testing.
Deployment: Using an offline-trained ML model as a prediction service is not sufficient for ML systems. To automatically retrain and deploy a model with ML systems, you may need to set up a multi-step pipeline. This pipeline increases complexity and calls on you to automate operations that data scientists formerly performed manually before deploying new models to train and validate them.
Production: In addition to poor coding, continuously changing data profiles can also cause ML models to function less well. In other words, models are more susceptible to decay than traditional software systems, and this decay must be taken into account. As a result, you must maintain your data summary statistics and keep an eye on your model's online performance to provide alerts or reverse decisions.
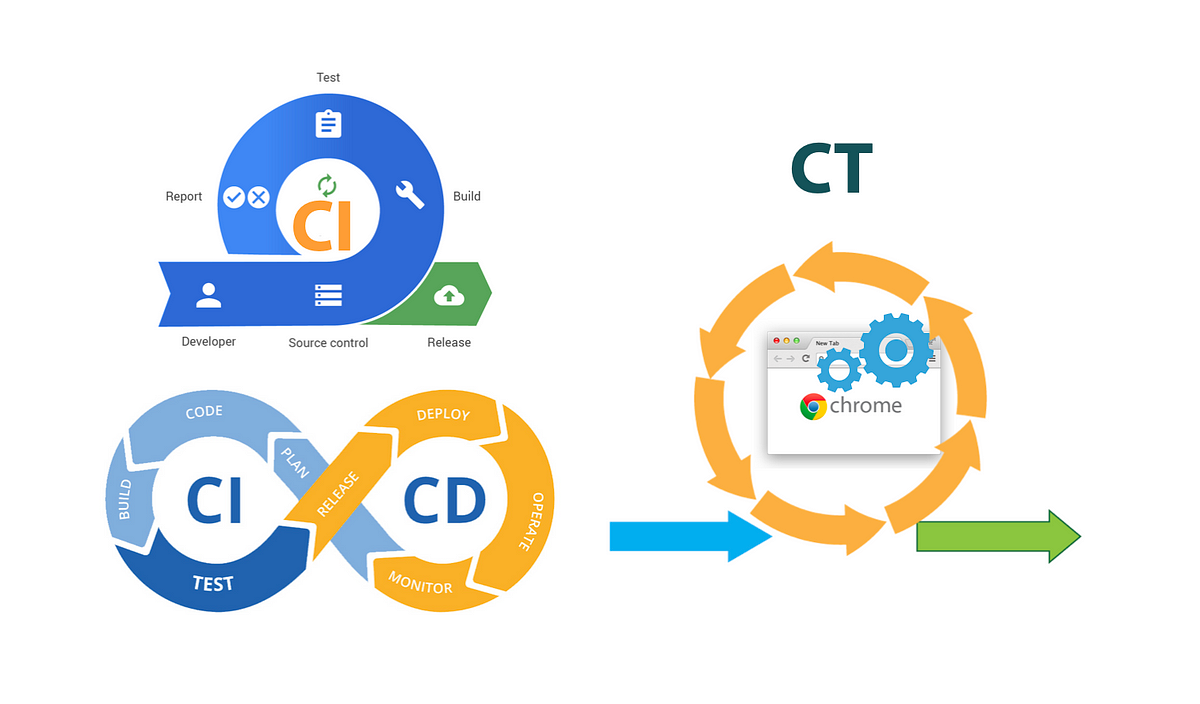
The continuous integration of source control, unit testing, integration testing, and continuous delivery of the software module or package are similarities between ML and other software systems. However, there are a few significant variations in ML:
Testing and validating data, data schemas, and models are now included in continuous integration (CI), in addition to testing and validating components and code.
A system (an ML training pipeline) that should automatically deploy a different service (a model prediction service) is what CD is all about rather than a specific software package or service.
CT is a novel characteristic of ML systems that are concerned with servicing and retraining the models automatically.
In any ML project, after you define the business use case and establish the success criteria, the process of delivering an ML model to production involves the following steps.
The degree of automation of these phases determines the ML process' maturity, which is a reflection of how quickly new models can be trained using fresh data or with fresh implementations. The three stages of MLOps are described in the parts that follow, from the most basic level, which involves no automation, to the level at which both ML and CI/CD processes are automated.
MLOps 0: Manual method

The following diagram shows the workflow of the process of a basic level of maturity, or level 0 for building and deploying ML models is entirely manual. Many data scientists and ML researchers can this kind of build state-of-the-art models, but their process for building and deploying ML models is entirely manual.
Characteristics of the MLOps level 0 process :
Interactive, script-driven, and manual procedure
Misalignment of operations and machine learning
Infrequent iterations of releases
No CI: CI is disregarded because little implementation change is anticipated.
No CD: CD is not taken into account because model version deployments are not common.
The deployment of the forecasting service is: Instead of delivering the whole ML system, the method is simply concerned with deploying the trained model as a prediction service (for instance, a microservice with a REST API).
Absence of active performance monitoring: The procedure does not keep track of or log model actions and predictions, which are necessary to identify model performance decline and other behavioral deviations.
For API configuration, testing, and deployment, the engineering team may have a complicated setup that takes into account security, regression, load, and canary testing. Additionally, when a new version of an ML model is promoted to service all prediction request traffic, it typically undergoes A/B testing or online trials before being deployed in production.
MLOps 1: ML pipeline automation

ML pipeline automation for CT
By automating the ML pipeline, level 1 aims to continuously train the model, allowing for continuous model prediction service delivery. You must add automated data and model validation processes, pipeline triggers, and metadata management to the pipeline to automate the process of using new data to retrain models in production.
Characteristics
Quick experiment
CT of the manufactured model
Operational-experimental symmetry
Pipelines and components using modularized code
Models are continuously delivered
Pipeline installation
Before a freshly deployed model delivers prediction for the online traffic, it goes through online model validation in addition to offline model validation, in a canary deployment or an A/B testing arrangement. A feature store is an optional extra component for level 1 ML pipeline automation. A feature store is a central location where you can standardize how features are defined, stored, and accessed for training and serving. To support both serving and training workloads, a feature store must have an API for both low-latency real-time serving and high-throughput batch serving for the feature values.
Information about each execution of the ML pipeline is recorded to help with data and artifact lineage, reproducibility, and comparisons. It also helps you debug errors and anomalies.
You can automate the ML production pipelines to retrain the models with new data, depending on your use case:
On-demand: Ad-hoc manual execution of the pipeline.
On a schedule: New, labeled data is systematically available for the ML system on a daily, weekly, or monthly basis. The retraining frequency also depends on how frequently the data patterns change, and how expensive it is to retrain your models.
On availability of new training data: New data isn't systematically available for the ML system and instead is available on an ad-hoc basis when new data is collected and made available in the source databases.
On model performance degradation: The model is retrained when there is noticeable performance degradation.
On significant changes in the data distributions (concept drift). It's hard to assess the complete performance of the online model, but you notice significant changes in the data distributions of the features that are used to perform the prediction. These changes suggest that your model has gone stale, and that needs to be retrained on fresh data.
You often manually test the pipeline and its components if you are managing a small number of pipelines and new implementations of the pipeline aren't frequently deployed. New pipeline implementations are also manually deployed. You also send the IT team the pipeline's tested source code for deployment in the target environment. When you deploy new models based on fresh data rather than fresh ML concepts, this setup is appropriate.
But you must quickly roll out new ML implementations and test out fresh ML concepts. If you oversee numerous ML pipelines in production, a CI/CD system is required to automate the development, testing, and deployment of ML pipelines.
MLOps 2: CI/CD pipeline automation

You need a powerful automated CI/CD system to update the production pipelines quickly and reliably. Your data scientists can quickly explore novel feature engineering, model architecture, and hyperparameter concepts thanks to our automated CI/CD solution. These concepts may be put into practice, and the new pipeline components can be built, tested, and deployed to the target environment automatically.
This MLOps setup includes the following components:
Source control
Test and build services
Deployment services
Model registry
Feature store
ML metadata store
ML pipeline orchestrator
The stages of the pipeline are as follows:
Experimentation and development
Continuous integration of a pipeline
Continuous delivery of a pipeline triggered automatically
Continuous delivery model
Monitoring
Before the pipeline begins a new iteration of the experiment, data scientists must still do the data analysis phase manually. A manual technique is also used for the model analysis step.
When new code is committed or published to the source code repository, the CI process might include built, tested, and packaged code. In addition to creating packages, executables, container images, and unit tests, each pipeline's component artifacts must also be tested.
The target environment is continuously receiving fresh pipeline implementations from your system, which in turn is receiving prediction services from the recently trained model. Consider checking the model's compatibility with the target infrastructure before deploying it, as well as testing data, and the prediction service by calling the service API with the expected inputs, and ensuring that you receive the expected response for quick and dependable continuous delivery of pipelines and models.
In conclusion,
Releasing your model as a prediction API is not the only way to utilize machine learning in a commercial setting. Instead, it entails implementing a machine learning pipeline that can automate model retraining and deployment. You may automatically test and release new pipeline implementations by setting up a CI/CD (CI : continuous integration and CD : continuous delivery) system. You can adapt to quick changes in your data and business environment using this solution. Not every procedure needs to be instantly transferred to a higher level. To enhance your ML system development and production automation, you can gradually incorporate these methods.
Feedback is welcomed.
And as always, use AI responsibly.
If you like this content please like it ten times, share the best you can and let a comment or feedback.
@#PeaceAndLove